데이터베이스 성능이란?
클라이언트(사용자) 요청에 대한 응답시간과 시간당 처리 할 수 있는 처리량이다.
1. Current User : 동시사용자
(1) Active User : 서버에 부하를 발생시키는 사용자 (클릭+이동)
(2) Inactive User : 서버에 요청을 보내고 있지 않은 사용자 (그냥보기)
2. TPS(Transaction Per Second) : 1초에 몇개의 트랜잭션을 처리했는가
3. Response Time : 요청 한 후부터 응답을 받을 때 까지의 시간
4. Resource : 한정된 값을 가진 시스템 구성 요소 (RAM, Memory)
데이터베이스 성능의 특성
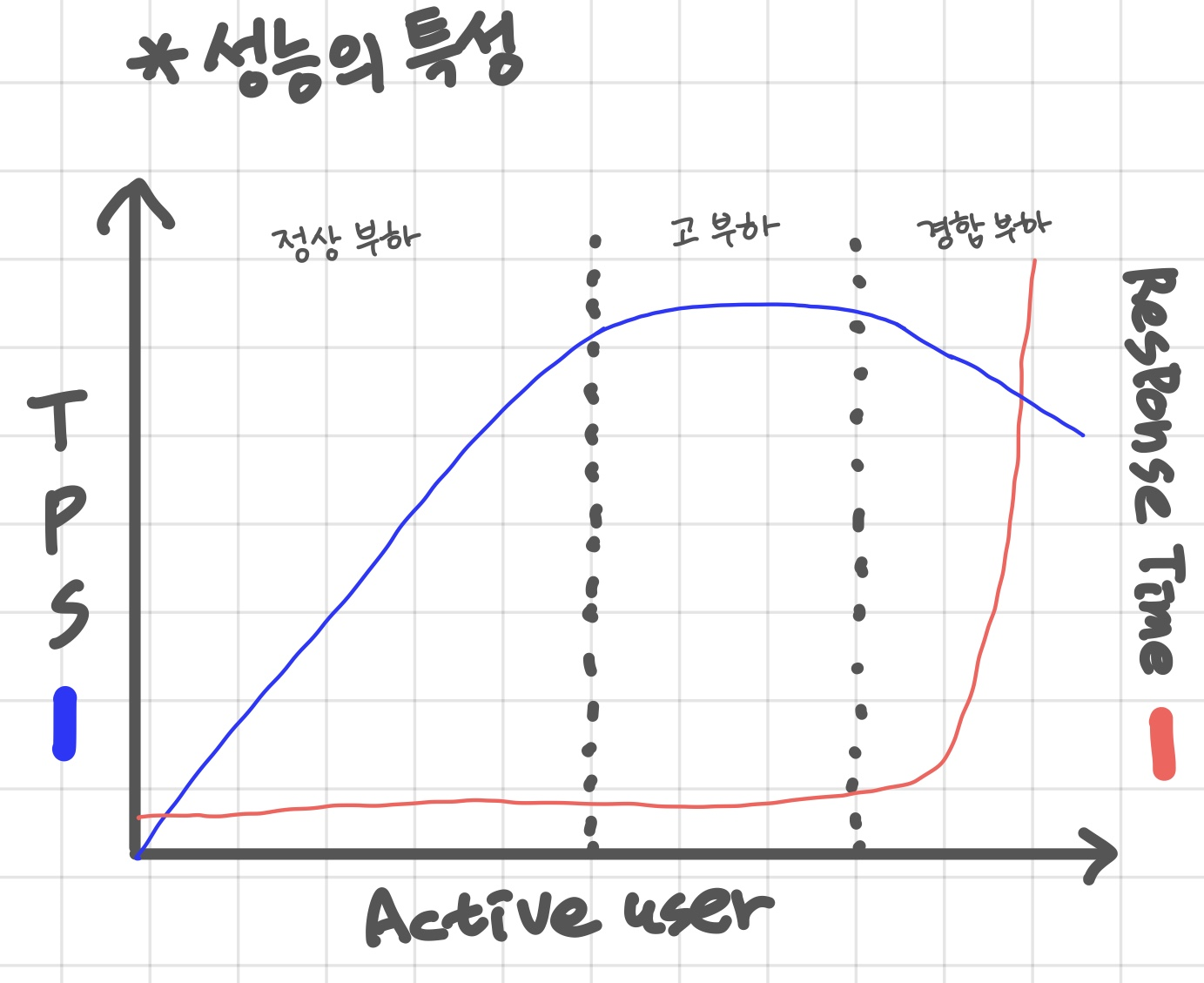
경합부하 구간에서 Response Time이 급격히 증가함.
TPS가 꺾이기 시작하는 구간부터가 고부하구간임.
성능 측정 대상
목표 TPS를 설정하고 정해진 응답시간 내에 모든 요청이 처리되는지 확인해야한다.
1. TPS - 건수기준 / Active User 기준 / Concurrent User 기준
2. Response Time - 3초 이내, 3초 이상부터 느리다고 느낌, 6초가 한계
3. Resources - CPU사용률(70%이하사용) / Memory(100% 이하 사용, Swap 현상 없어야함) / 디스크 사용률(100% 미만, 디스크 소요시간 2~3ms)
데이터베이스 병목의 원인
취급하는 데이터가 많다.
데이터의 총 크기는 지속적으로 증가한다.
DBMS 성능의 원인은 대부분 I/O에서 발생함
I/O를 줄이면 병목을 줄일 수 있다 !
블록 I/O를 줄이기 위한 모델 설계, DBMS 환경 구축, SQL 튜닝 등의 기술이 발달함.
프로세스 생성 주기
여러 프로세스는 하나의 CPU를 공유할 수 있지만, 특정 순간에는 하나의 프로세스만 CPU를 사용함
-> wating이 생길 수 밖에 없다
일하던 프로세스도 디스크에서 데이터를 읽어야 할 땐 CPU를 OS에 반환하고 wating 상태에서 I/O가 완료되길 기다림.
절대적인 I/O의 횟수를 줄이는 것이 성능 개선의 핵심
SQL문의 실행 과정
1. SQL 파싱 : 사용자로부터 SQL을 받으면 SQL Parser가 Parsing을 진행
2. SQL 최적화 : 옵티마이저의 역할. 다양한 실행 경로 중 가장 효율적인 하나를 선택(DBMS 성능의 가장 핵심)
3. 로우 소스생성 : 옵티마이저가 선택한 경로를 실제 실행 가능한 코드 또는 프로시저 형태로 포맷팅
옵티마이저
SQL 옵티마이저는 사용자가 원하는 작업을 가장 효율적으로 할 수 있는 최적의 데이터 엑세스 경로를 선택해줌
DBMS의 핵심 엔진이다.
통계정보를 이용해 각 실행 계획의 예상 비용을 선정한 후 최저 비용을 나타내는 실행 계획을 선택함.
-> 옵티마이저가 실수하면 ? SQL 튜너가 잡아준다.
비용은 쿼리를 수행하는 동안 발생될 것으로 예상되는 I/O횟수 또는 예상 소요 시간을 표현한 값임.
언제까지나 예상치일뿐. 실행 경로를 선택하기 위해 옵티마이저가 통계 정보를 활용해 계산해낸것.
옵티마이저가 참조하는 통계정보
- 테이블의 행수 및 열수
- 각 열의 길이와 데이터형
- 테이블의 크기
- 열에 대한 기본키나 NOT NULL 제약정보
- 열 값에 대한 통계
- 인덱스에 대한 통계
Table Full Scan : 테이블의 전체 레코드를 처음부터 끝까지 읽기
Index Range Scan : 인덱스를 이용하여 테이블의 일부 레코드에만 엑세스
인덱스를 이용한 성능 개선
인덱스는 큰 테이블에서 소량의 데이터를 검색할 때 사용.
인덱스 튜닝이 무엇보다 중요함.
인덱스 튜닝의 시작은 효율적인 인덱스 컬럼으로 인덱스를 구성하는 것.
변별력이 좋은 컬럼을 앞으로 빼야함 !!
인덱스 구조는 주로 B*Tree 구조를 이용함.
데이터 유지하기 위해 자주 사용하는 구조 / 이진 탐색으로 효율적이고 빠른 탐색 가능
데이터 일부만 읽고 멈출 수 있음.
범위스캔가능
인덱스를 스캔하는 이유 : 검색조건을 만족하는 데이터를 빨리 찾고, 거기서 ROWID를 얻기 위함
ROWID : 리프블럭에서 데이터를 찾고, 다시 TABLE로 갈때 그 행을 구별할 수 있는 ID / 주소값
인덱스의 장점
인덱스는 데이터베이스의 일반적인 성능 향상 수단이다.
SQL문을 변경하지 않아도 성능 개선 가능.
테이블 데이터에 영항을 주지 않는다.
인덱스만 잘 만들면 극적인 성능 향상도 가능함.
특정 SQL문이 사용하기에 비효율적인 인덱스인 경우 테이블 풀 스캔보다 느릴 수있음
무조건 적인 사용은 안된다.
인덱스의 역효과
갱신 오버헤드 / 저장소 용량 차지 / 느린 성능 / 의도한 것과 다른 인덱스 사용
인덱스 생성 원칙
테이블의 크기 : 크기가 큰 테이블에 인덱스가 필요함 / 작은 테이블은 Tale Full Scan이 효과적인 경우가 많음
기본키에는 이미 인덱스가 형성되어있음
선택도가 낮은 칼럼(변별력이 좋은)에 만들면 극적인 성능 향상 가능
범위조건이 아닌, =조건 칼럼에 만들어야함
'SQL' 카테고리의 다른 글
| [SQLite3] DDL 실습 ( CREATE / RNAME / ADD / DELETE ) / CSV 파일 가져오기 (0) | 2023.04.05 |
|---|---|
| 백업 및 복구 (0) | 2022.10.09 |
| 테이블 설계 (1) | 2022.10.09 |
| DA# 데이터 모델링 실습 (0) | 2022.10.09 |
| 트랜잭션 (0) | 2022.10.09 |