import pandas as pd
fname = './emp.csv'
emp = pd.read_csv(fname, encoding='cp949')
print(emp)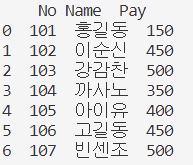
pd.read_csv 함수로 csv 파일을 읽을 수 있음
loc / iloc
# loc
# 문제1 강감찬출력
print(emp.loc[2])
# # 문제2 2행~5행
print(emp.loc[2:5]) #2행~5행
loc로 원하는 행을 지정해서 불러올 수 있다.
print(emp.loc[2, 'Name':'Pay'])
loc[행, 열] : 원하는 행에서 특정 열만 지정하여 불러오기도 가능
# #loc
print(emp.loc[0:6, 'No' : 'Name'])
# #iloc
print(emp.iloc[0:6, 0:2])
loc : 원하는 columns을 문자열로 지정해야함
iloc : 원하는 columns을 숫자로 지정해야함
score.csv 파일 활용하기
import pandas as pd
score = './data/score.csv'
score = pd.read_csv(score, encoding='cp949')
print(score)
dept = 103인 행만 추출하기
print(score[score.dept==103])
영어점수 총점 / 최소 / 최대 / 평균 구하기
from statistics import mean,median
a = score.kor
b = score.eng
c = score.mat
d = score.dept
print('최고점수:',max(c))
print('최저점수:',min(c))
print('총점수:',sum(c))
print('평균점수:',round(mean(c),2))
평균은 반올림하여 소수점 2번째 자리 까지만 나오게함.
mean은 사용하기 전에 import가 필요하다.
import mean안쓰고 평균 구하기
print('평균점수:',round(sum(c)/len(c),2))sum으로 모두 더하고, len으로 횟수만큼 나누면 된다.
dept 빈도수 구하기
dept = score['dept']
a = pd.value_counts(dept)
print('부서의 빈도수\n',a)
pd.value_counts를 사용하면 원하는 열의 각 빈도수를 구할 수 있음
열에 평균 점수, 총 점수 추가하기
# 개인별 총점 / 평균 오른쪽 끝 열에 추가
score = pd.DataFrame(score)
mean1 = score.mean(axis='columns')
sum1 = score.sum(axis='columns')
score['mean'] = mean1
score['sum'] = sum1
print(score)
axis='columns' : 작업 결과가 열로 나타난다. 각행의 모든 열에 동작
score.mean(axis='columns) 즉, 각 행의 모든 열의 평균을 구함
mean과 sum을 구한 후, 새로운 열로 추가해주었다.
-axis에 대한 자세한 설명이 나온 블로그-
[파이썬 pandas] 판다스 매개변수 axis의 의미를 알아보자
판다스를 사용하다 보면 평균 계산, 데이터프레임 열이나 행 삭제 작업등을 할 때 axis(축)을 지정해야 합니다. 축을 넣어야 할 때면 0을 넣어야 하는지 1을 넣어야 하는지 헷갈릴 수 있습니다. 이
hogni.tistory.com
순위세우기
# 순위추가
score['rank'] = score['mean'].rank(ascending=False,method='max')
# 순위대로 정렬
print(score.sort_values(by='rank',ascending=True, ignore_index=True))
.rank함수로 순위를 만든 후, ascending=True 내림차순 정렬, ignore_index=True로 인덱스를 새로 설정
'PYTHON > 강의복습' 카테고리의 다른 글
| [22.10.19] 판다스 ( Seriese / 데이터프레임 / 인덱스 ) (0) | 2022.10.19 |
|---|---|
| [22.09.13] 클래스와 객체 ( class / object / __init__ ) (0) | 2022.09.13 |
| [22.09.06] 파이썬 데이터타입( 딕셔너리 / set ) (0) | 2022.09.06 |
| [22.09.06 ] 파이썬 데이터타입( 리스트 / 함수 / 튜플 / 시퀀스 ) (0) | 2022.09.06 |
| [22.09.05] 1일차 ( 변수 / 문자열 ) (0) | 2022.09.05 |