yes24에서 IT 신간 도서 정보 추출하기
# YES24에서 IT신간 정보 추출(도서명, 출판사명) - 아래쪽
site<- "http://www.yes24.com/24/Category/NewProductList/001001003?sumGb=04&PageNumber=2"
html <- read_html(site)
html
nodes = html_nodes(html, "td.goodsTxtInfo")
html_text(nodes)
for (node in nodes){
# 제목
title_node = html_node(node, "p > a")
title = html_text(title_node, trim=T) #쓸데없는 공백들 없애기
print(paste("제목:", title))
# 작가명
author_node = html_node(node, "div > a:first_child")
author = html_text(author_node)
print(paste("작가명:", author))
# 출판사
publisher_node = html_node(node, "div > a:last_child")
publisher = html_text(publisher_node)
print(paste("출판사:", publisher) )
}
작가와 출판사가 "div > a" 안에 같이 있어서, "div > a:first_child" 와 "div > a:last_child"로 구분해서
데이터를 가져올 수 있었다.
전체 페이지 가져오기
http://www.yes24.com/24/Category/NewProductList/001001003?sumGb=04&PageNumber=3
해당 사이트는 페이지를 넘길 때 마다 url의 마지막에 "PageNumber= " 의 숫자가 바뀌는 것을 확인했다 !
이를 이용하여 전체 페이지 정보를 가져와보자.

site <- "http://www.yes24.com/24/Category/NewProductList/001001003?sumGb=04"
# 페이지 지정
i = 1
url = paste0(site, "&PageNumber=", i)
print(url)
html <- read_html(url)
# 정보 가져오기
nodes = html_nodes(html, "td.goodsTxtInfo")
# 페이지 당 몇개의 책이 있는지
print(length(nodes))
# 데이터가 더 없으면 종료
if( length(nodes)==0)
여기에 아까 만들어놓은 정보 가져오기 코드를 합체시킨다.
site <- "http://www.yes24.com/24/Category/NewProductList/001001003?sumGb=04"
i<-1
books=NULL
while(TRUE) #무한루프
{
url = paste0(site, "&PageNumber=", i)
print(url)
html <- read_html(url)
nodes = html_nodes(html, "td.goodsTxtInfo")
nodes
# 페이지당 몇개의 책이 있는지
print(length(nodes))
if( length(nodes)==0) #더이상 데이터를 가져오지 못할때 종료한다
break #중간에 while문을 종료한다
for (node in nodes){
title_node = html_node(node, "p > a")
title = html_text(title_node, trim=T) #쓸데없는 공백들 없애기
#print(paste("제목:", title))
temp_nodes = html_nodes(node, "div > a")
#print( length(temp_nodes ))
temp = html_text(temp_nodes)
author = paste(temp[-length(temp)], collapse=",")
#print(author )
#print(paste("출판사 :", temp[ length(temp)] ) )
publisher<-temp[ length(temp)]
books <- rbind(books, data.frame(title, author, publisher))
}
i<-i+1
}
View(books)
write.csv(books, "yes24_books.csv", fileEncoding="CP949")
View(book) 결과

csv 파일도 잘 만들어진 것을 확인 !
홈페이지에서 이미지 읽어오기
http://unico2013.dothome.co.kr/productlog.html
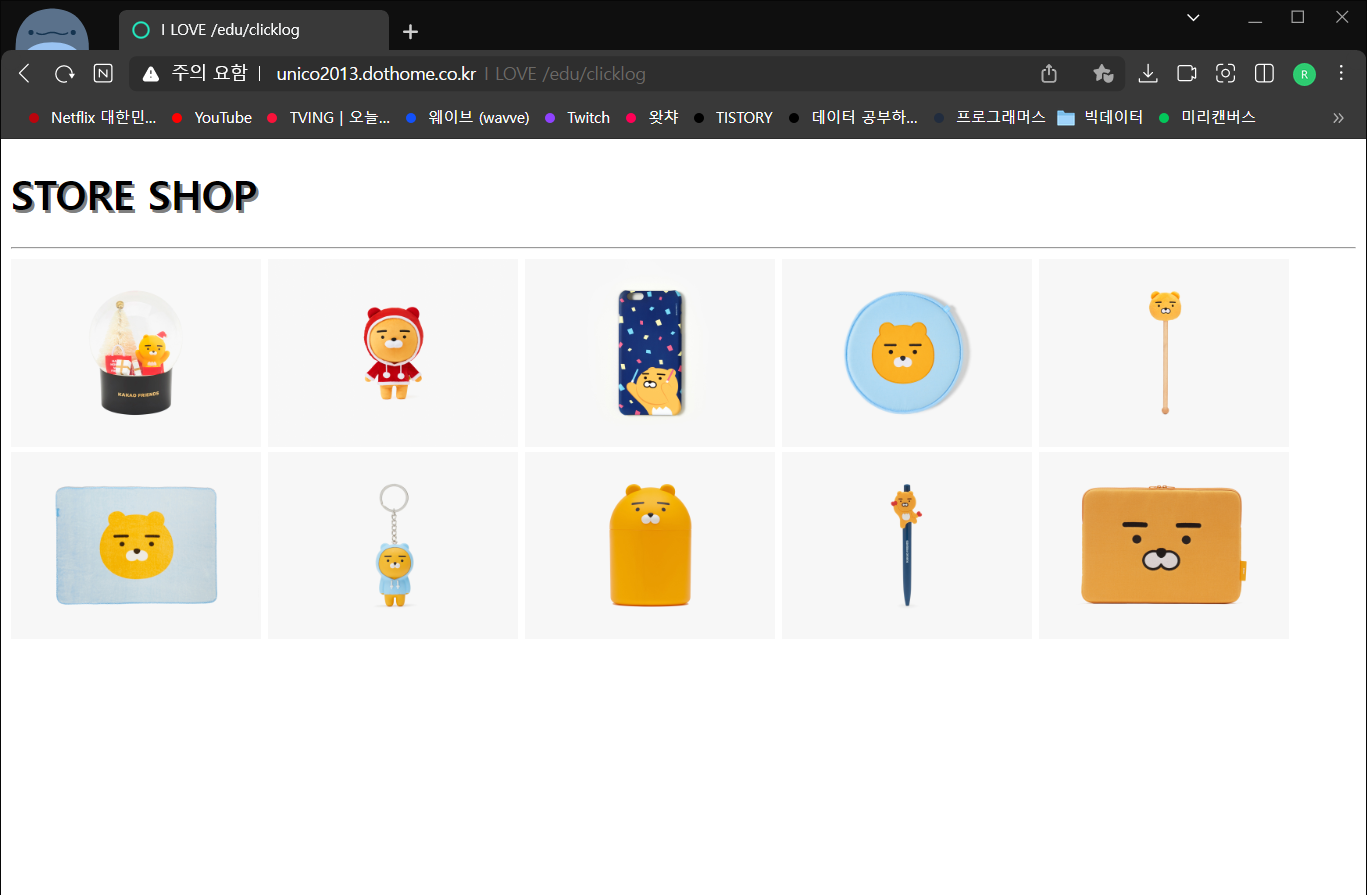
이 사이트에서 사진을 가져올 것이다 !
# 이미지 읽어오기
res <- GET("http://unico2013.dothome.co.kr/productlog.html")
html <- content(res)
img <- html_nodes(html, 'img')
img
#속성값을 가져올때는 html_attr("속성") a태그의 href 만
img.src = html_attr(img, 'src')
img.src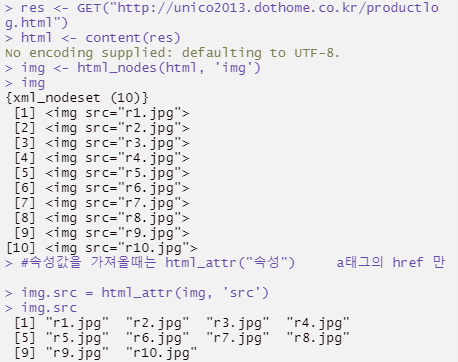
html_attr 을 사용하면 이미지의 이름과 속성만 볼 수 있다.
No encoding supplied: defaulting to UTF-8. <- 이거.. 왜뜨는걸까?
이미지는 잘오는듯하다..
res = GET("http://unico2013.dothome.co.kr/r1.jpg")
writeBin(content(res, 'raw'), paste0("c:/Temp/", "r1.jpg"))GET("이미지 주소 복사") 를 넣고,
writeBin으로 첫번째 이미지를 먼저 저장해보았다.
* GET( ) : 데이터에 정보를 주거나, 정보를 가져올 수 있는 함수
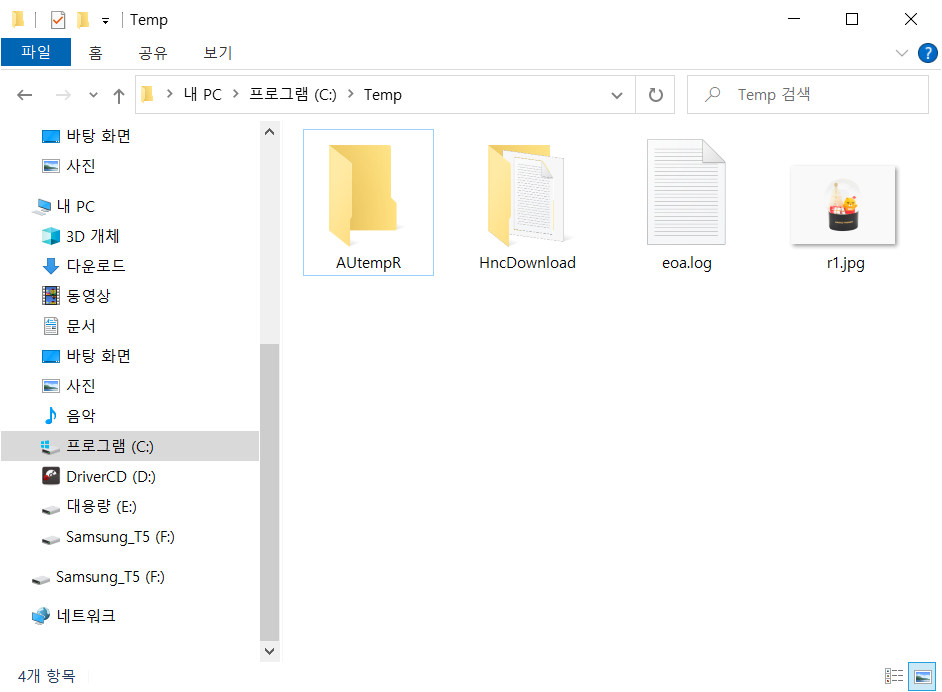
저장이 잘 된 모습 !
이제 홈페이지의 모든 이미지를 가져와 보자.
for(i in 1:length(img.src)){
res = GET(paste0("http://unico2013.dothome.co.kr/", img.src[i]))
writeBin(content(res, 'raw'),
paste0("c:/r_workspace/Data/output/images/",img.src[i]))
}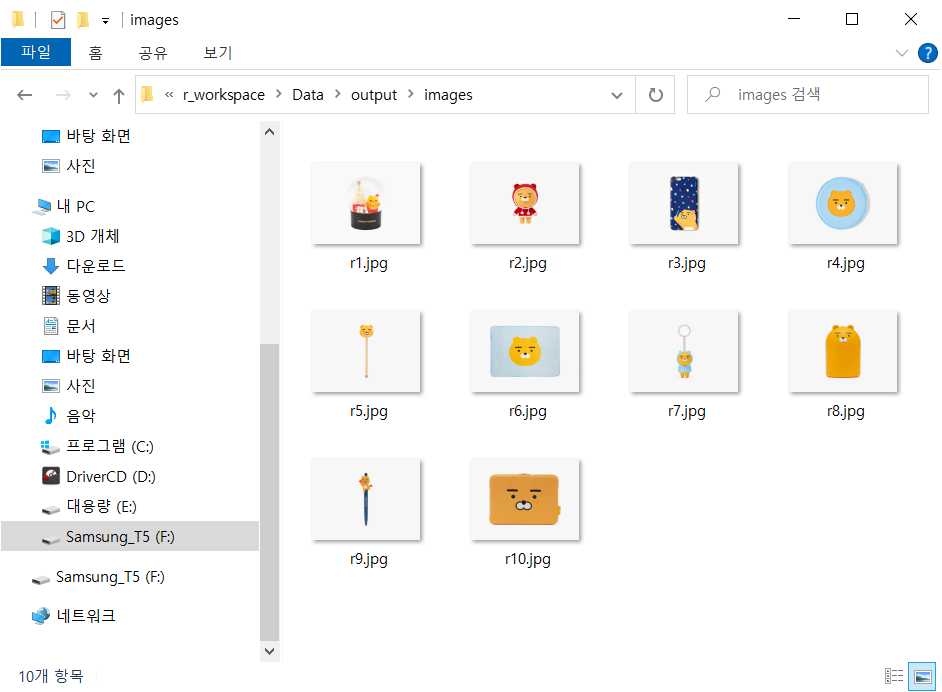
for 문을 사용하여 모든 이미지를 다 가져오기 성공 !
~ 오늘의 공부 후기 ~
이제 R로 홈페이지에서 원하는 정보를 모아오는 것은 능숙해진 것 같다 !
점점 더 고수가 되는 느낌 ~
'R > 강의복습' 카테고리의 다른 글
| [22.08.25] Selenium(셀레니윰) 활용해서 데이터 크롤링하기 (0) | 2022.09.04 |
|---|---|
| [22.08.25] 13일차 API활용하기( 카카오 / 서울 빅데이터 ) (0) | 2022.09.04 |
| [22.08.23] 11일차 데이터크롤링 ( 영화 평점 가져오기 ) (0) | 2022.09.03 |
| [22.08.22] 10일차 (데이터 크롤링 / 뉴스 크롤링 ) (0) | 2022.09.03 |
| [22.08.22] 10일차 (인터랙티브 그래프 / 시계열 그래프 / 산포도 / 빈도수그래프) (0) | 2022.09.03 |