셀레니윰 설치하기
https://blog.naver.com/bb_/222637214732
[Python] 파이썬 자동화 기초 : 웹 브라우저 제어, 크롬 자동화, 셀레니움(selenium) 명령어 모음
[Python] 파이썬 자동화 기초 : 웹 브라우저 제어, 크롬 자동화, 셀레니움(selenium) 명령어 모음 파이썬...
blog.naver.com
위 블로그를 참고하여 설치하였다. 설명이 친절하다 !
셀레니윰 실행하기
1. 셀레니윰 설치후, 셀레니윰이 있는 폴더에서 cmd를 열어준다.
2. cmd창에
" java -Dwebdriver.gecko.driver="geckodriver.exe" -jar selenium-server-standalone-4.0.0-alpha-1.jar -port 4445 " 를 입력한다
3. 코드를 실행시킨다
※ 주의 : 절대 cmd 창을 끄지말것!!
install.packages("RSelenium")
library(RSelenium)
remDr <- remoteDriver(remoteServerAddr = "localhost",
port = 4445, browserName = "chrome")
remDr$open()
chrome 창이 오픈된다 !
# 브라우저에서 페이지 이동하기
remDr$navigate("http://www.google.com")
이렇게 지정한 홈페이지로 이동시킬 수 있다.
구글에 PYTHON 검색시키기
# 컨텐츠 추출하기
# name = q -> 검색창
webElem <- remDr$findElement(using="css selector", "[name='q']")
# input 태그에 검색어를 입력한다 / 검색창에 python이라고 쓰고나서 엔터키를 눌러라
webElem$sendKeysToElement( list("PYTHON", key="enter"))
도대체 " name = q " 가 무슨 뜻일까 !! 했는데 google의 css에서 name= q가 검색창이였다..
검색시키기위해 검색창을 찾은것 !!
css는 홈페이지의 겉모습 ? 정도로 이해했다.
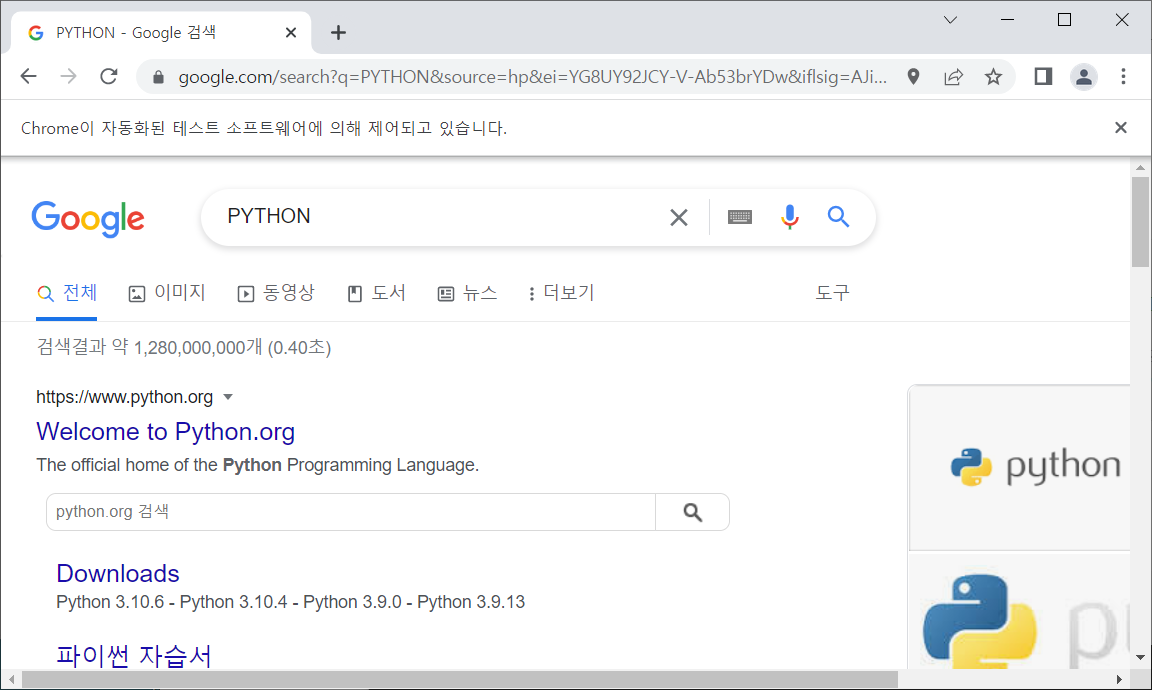
열린 홈페이지에서 자동으로 PYTHON이 검색 된 모습 !
네이버에서 검색하기
# 네이버로 이동후 검색어 입력하기
remDr$navigate("http://www.naver.com")
# id가 있을 경우id로 접근할 때
webElem <- remDr$findElement(using="css selector", "#query")
webElem$sendKeysToElement( list("PYTHON", key="enter"))
네이버는 #query로 검색창을 찾을 수 있나보다
셀레니윰으로 네이버 웹툰 댓글 크롤링하기
네이버 웹툰 댓글 들어가기
url <-"http://comic.naver.com/comment/comment?titleId=712362&no=184"
remDr$open()
remDr$navigate(url)
전체 댓글 누르기
# 전체 댓글 누르기
more <- remDr$findElement(using="css selector",
"#cbox_module > div > div.u_cbox_view_comment > a > span.u_cbox_in_view_comment")
more$getElementText()
more$clickElement()
#cbox_module > div > div.u_cbox_view_comment > a > span.u_cbox_in_view_comment
댓글 내용 가져오기
# 댓글 내용 가져오기
re <- remDr$findElements(using="css selector","span.u_cbox_contents")
comment <- sapply(re, function(x){x$getElementText() })
comment <- unlist(comment)
comment
댓글 페이지 이동하기
# 페이지 이동하기
for (i in 4:12){
nextCss <- paste0("#cbox_module > div > div.u_cbox_paginate > div > a:nth-child(", i, ") >span")
print(nextCss)
nextPage <- remDr$findElement(using="css selector", nextCss)
nextPage$clickElement()
# 시간 지연 필요 / 2초 대기
Sys.sleep(2)
}
실행하면 혼자서 페이지가 이동한다.
10페이지 까지 댓글 다 모아오기
위에서 만든 코드들을 다합쳐서 10페이지 댓글 내용을 가져오자 !
# 10페이지 까지 댓글 가져오기
url<-"http://comic.naver.com/comment/comment?titleId=712362&no=184"
remDr$open()
remDr$navigate(url)
# 1. 전체 댓글 보기 클릭
more <- remDr$findElement(using="css selector",
"#cbox_module > div > div.u_cbox_view_comment > a > span.u_cbox_in_view_comment")
more$getElementText()
more$clickElement()
dataList <- NULL
# 페이지 이동하기
for (i in 4:12){
nextCss <- paste0("#cbox_module > div > div.u_cbox_paginate > div > a:nth-child(", i, ") >span")
print(nextCss)
nextPage <- remDr$findElement(using="css selector", nextCss)
if( length(nextPage)==0) #10페이지 못넘어 가는 경우도 있음
break
nextPage$clickElement()
# 시간 지연 필요 / 2초 대기
Sys.sleep(2)
re <- remDr$findElements(using="css selector","span.u_cbox_contents")
comment <- sapply(re, function(x){x$getElementText() })
comment <- unlist(comment)
dataList <- c(dataList, comment)
}
dataList
약 135개의 댓글이 수집되었다 !
~ 오늘의 공부후기 ~
셀레니윰이라는 신기한 것을 배웠다 !
웹페이지가 혼자 작동하는 것이 참 신기했다.
이런걸로 혼자 돌아가는 매크로를 만드는 건가?? 싶었다
'R > 강의복습' 카테고리의 다른 글
| [22.08.25] 13일차 API활용하기( 카카오 / 서울 빅데이터 ) (0) | 2022.09.04 |
|---|---|
| [22.08.24] 12일차 ( 신간 도서 정보 추출하기 / 홈페이지 이미지 가져오기 ) (0) | 2022.09.04 |
| [22.08.23] 11일차 데이터크롤링 ( 영화 평점 가져오기 ) (0) | 2022.09.03 |
| [22.08.22] 10일차 (데이터 크롤링 / 뉴스 크롤링 ) (0) | 2022.09.03 |
| [22.08.22] 10일차 (인터랙티브 그래프 / 시계열 그래프 / 산포도 / 빈도수그래프) (0) | 2022.09.03 |